# Лекция 16. Кэш-память
## Содержание
- [Лекция 16. Кэш-память](#лекция-16-кэш-память)
- [Содержание](#содержание)
- [Кэш-память](#кэш-память)
- [Иерархия памяти](#иерархия-памяти)
- [Локальность данных](#локальность-данных)
- [Характеристики кэш-памяти](#характеристики-кэш-памяти)
- [Существует 3 вида кэш-памяти](#существует-3-вида-кэш-памяти)
- [Анализ производительности](#анализ-производительности)
- [Кэш прямого отображения](#кэш-прямого-отображения)
- [Идентификация строки](#идентификация-строки)
- [Множественно-ассоциативный кэш](#множественно-ассоциативный-кэш)
- [Полностью ассоциативный кэш](#полностью-ассоциативный-кэш)
- [Длина строки (блока)](#длина-строки-блока)
- [Алгоритмы замещения данных](#алгоритмы-замещения-данных)
- [Стратегии чтения и записи в кэш](#стратегии-чтения-и-записи-в-кэш)
- [Основные оптимизации кэш-памяти](#основные-оптимизации-кэш-памяти)
- [Основные материалы лекции](#основные-материалы-лекции)
- [Дополнительные материалы к лекции для саморазвития](#дополнительные-материалы-к-лекции-для-саморазвития)
## Кэш-память
С 80-х годов процессоры начали превосходить по производительности память *(рис. 1)*. Этот разрыв в скоростях привёл к потребности в быстром буфере памяти, который мог бы уменьшить задержку при обращении к данным. В 60-70-х годах начались эксперименты и исследования в области быстрых буферов, что привело к созданию **кэш-памяти**.
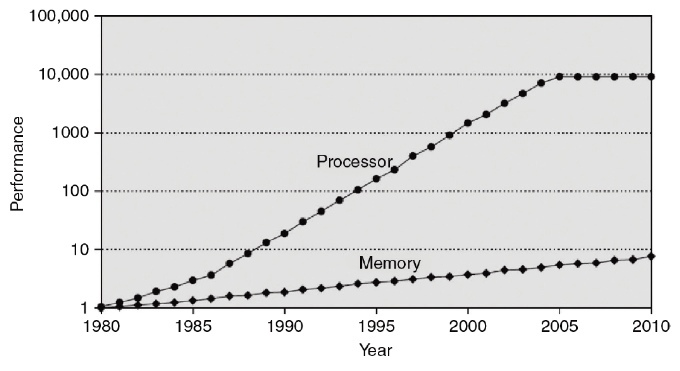
*Рис. 1. Изменение в производительности процессоров и памяти с 80-х годов.*
**Что такое кэш-память?**
**Кэш-память** — это небольшой сегмент высокоскоростной памяти, обычно на базе **SRAM** ([**Static Random-Access Memory**](../15.%20Memory.md), расположенный непосредственно на процессоре или рядом с ним. Её главная функция — временное хранение тех данных, к которым процессор часто обращается. Основная цель такой памяти — уменьшить задержку доступа к данным, служа мостом между процессором и основной оперативной памятью.
**Для чего нужна кэш-память?**
Основное **предназначение кэш-памяти** — ускорение доступа процессора к часто используемым данным и командам, минимизируя зависимость от более медленной основной памяти. Благодаря этому, время реакции системы сокращается, делая её более отзывчивой и эффективной.
## Иерархия памяти
**Иерархия памяти** — это объединение разных типов памяти с целью получения большой, дешевой и быстрой памяти, с чем можно более подробно ознакомиться на *(рис. 2)*. Наивысший уровень иерархии (**Cache**) обычно является наиболее быстрым и наименее емким, в то время как нижний уровень обычно имеет не только наибольший объем, но и наибольшую задержку (**Secondary (external) Memory**).
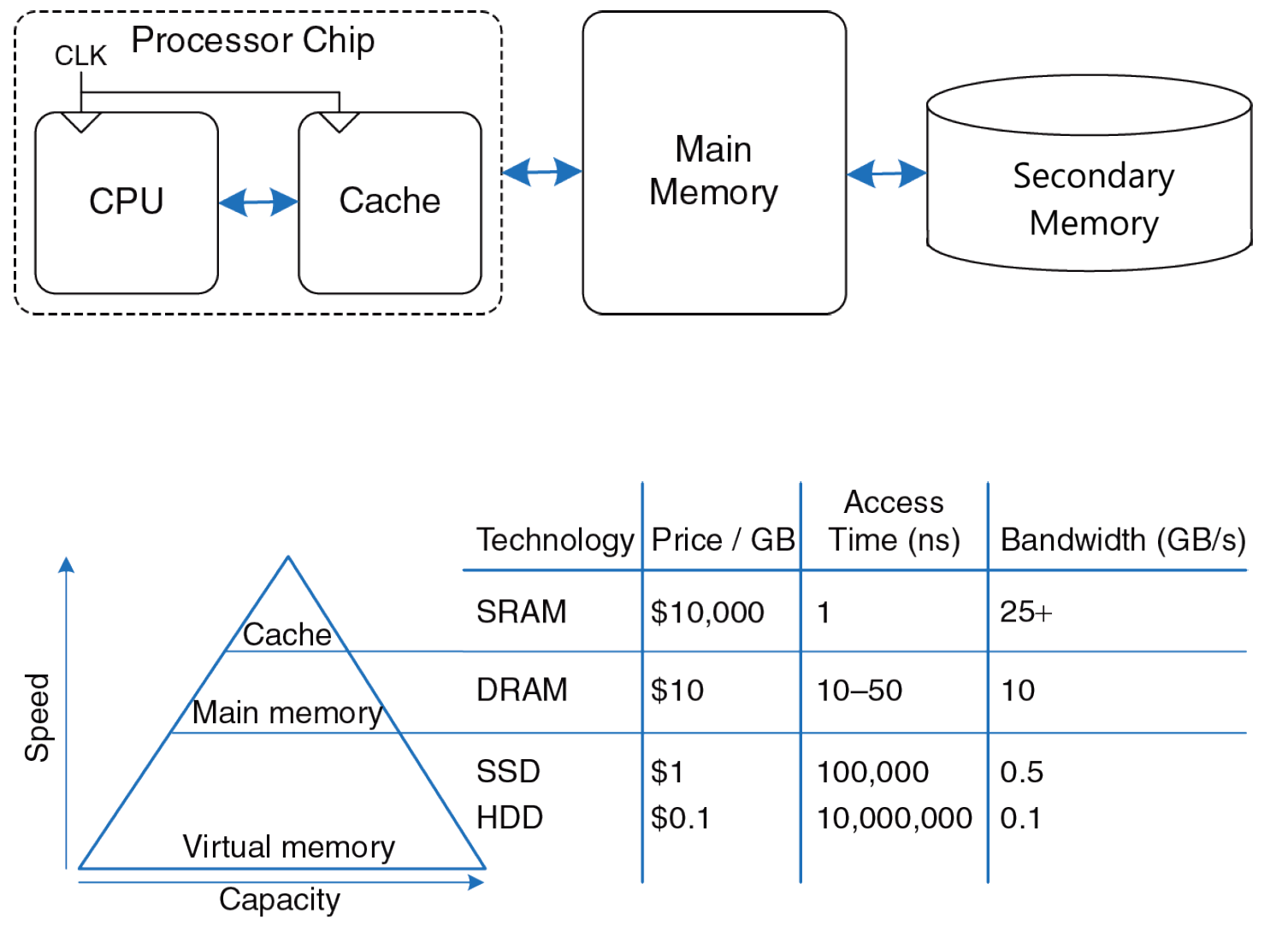
*Рис. 2. Схема расположения разных типов памяти и пирамида иерархии памяти.*
**SRAM** (Static Random-Access Memory) — тип быстрой полупроводниковой памяти, который сохраняет данные без необходимости периодического обновления. Используется в кэш-памяти процессоров из-за своей высокой скорости.
**DRAM** (Dynamic Random-Access Memory) — тип полупроводниковой памяти, который требует периодического обновления для сохранения данных.
**SSD** (Solid-State Drive) — устройство хранения данных, работающее на основе NAND-памяти.
**HDD** (Hard Disk Drive) — устройство хранения данных, использует магнитные диски для записи и чтения данных, имеет больший объем по сравнению с SSD, но скорость доступа к данным обычно ниже.
Несмотря на то что кэш-память во много раз быстрее основной памяти, она еще в большее число раз меньше её. Разумеется, объем кэша меняется от процессора к процессору, но для определенности возьмем следующий пример: допустим, в процессорной системе кэш 32МБ, а объем оперативной памяти — 32ГБ. Получается, кэш меньше основной памяти в 1024 раза. Как же так получается, что, обращаясь в кэш, процессор умудряется получать именно те данные, которые запрашивал? Ведь если вероятность того, что кэш содержит нужные процессору данные, составляет 1/1024-ую, то он будет ухудшать производительность системы, а не улучшать ее. Этому способствует такое явление как **локальность данных**.
## Локальность данных
[Локальность данных](https://en.wikipedia.org/wiki/Locality_of_reference) — это набор наблюдений (закономерностей), благодаря которым процессорная система становится чуть более предсказуемой. Эта предсказуемость позволяет использовать кэш эффективно.
Существует несколько видов локальности, но в данный момент необходимо выделить два ключевых:
- **временнáя локальность**: если произошло обращение к данной ячейке памяти, высока вероятность того, что в скором времени обратятся к этой же ячейке памяти;
- **пространственная локальность**: если произошло обращение к данной ячейке памяти, высока вероятность того, что в скором времени обратятся к соседним ячейкам памяти.
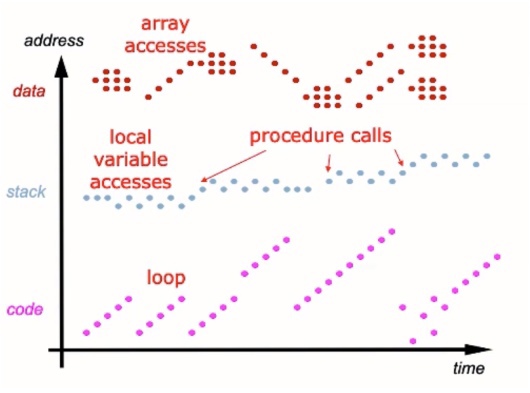
*Рис. 3. Примеры пространственной и временно́й локальности для разных типов памяти.*
**Перед созданием Кэш-памяти нам нужно задаться 4-мя вопросами**:
- Где могут быть размещены данные в кэш-памяти? ([**Размещение строки в разных видах кэшах-памяти**](#существует-3-вида-кэш-памяти))
- Как найти данные в кэш-памяти? ([**Идентификация строки**](#идентификация-строки))
- Какие данные нужно заместить при заполненной кэш-памяти? ([**Алгоритмы замещение строки**](#алгоритмы-замещения-данных))
- Что происходит при записи в кэш-память? ([**Стратегия записи**](#стратегии-чтения-и-записи-в-кэш))
## Характеристики кэш-памяти
- Ёмкость – ***C*** (capacity)
- Число наборов – ***S*** (set)
*Любая Кэш-память обладает числом наборов. Каждая ячейка основной памяти может претендовать только на свой набор.*
- Длина строки (блока) – ***b*** (block)
*Порция перемещения данных между разными уровнями иерархии памяти.*
- Количество строк (блоков) – ***B*** = C/b
- Степень ассоциативности – ***N***
*Количество места в кэш-памяти, на которое претендует конкретная строка. Каждая ячейка может располагаться только в одном наборе, один набор может состоять из нескольких строк — это и есть степень ассоциативности.*
**Наборы в кэш-памяти**:
Кэш дробится на подгруппы, которые называются наборами. Их особенность заключается в том, что каждая ячейка памяти закреплена за своим набором. Иными словами, ячейка памяти может быть загружена не в любое место кэша.
- Кэш ***состоит из S наборов***, каждый из которых содержит одну или несколько строк.
- Взаимосвязь между адресом в памяти и расположением в кэш называется ***отображением***.
- Каждый адрес в памяти отображается в ***один и тот же набор кэша***.
### Существует 3 вида кэш-памяти
- [Кэш прямого отображения](#кэш-прямого-отображения) – Набор S содержит только одну строку – ***S = B***
- [Множественно-ассоциативный кэш](#множественно-ассоциативный-кэш) – Каждый набор S состоит из N строк – ***S = B/N***
- [Полностью ассоциативный кэш](#полностью-ассоциативный-кэш) – Имеет только один набор ***S = 1***
#### Анализ производительности
- Доля попаданий (hit rate - **HR**)
- Доля промахов (miss rate - **MR**)
- MR = Число промахов⁄Общее число доступов к памяти = 1 - HR
- HR = Число попаданий⁄Общее число доступов к памяти = 1 - MR
- **AMAT** - average memory access time
- AMAT = tcache + MRcache *(tMM + MRMM* tVM)
Пример:
| Уровень памяти | Время доступа в тактах | Процент промахов |
|:-------------------|:----------------------:|:----------------:|
| Кэш-память | 1 | 10% |
| Оперативная память | 100 | 0% |
*AMAT* = 1 + 0.1 *(100) = 11
Какой должен быть MR, чтобы снизить AMAT до 1.5 тактов?
1 + m* (100) = 1.5 -> m = 0.005%
## Кэш прямого отображения
Рассмотрим *(рис. 4)*. Здесь представлена основная память, имеющая 32-х битный адрес. В этом примере кэш будет состоять из 8 наборов при длине строки, равной одному слову.

*Рис. 4. Структура кэша, состоящего из 8 наборов, где длина строки равна одному слову.*
### Идентификация строки
Каждая ячейка памяти претендует только на свой набор и имеет свой уникальный адрес. На *(рис. 5)* подробнее рассмотрим, как уникальный адрес делится на несколько частей:
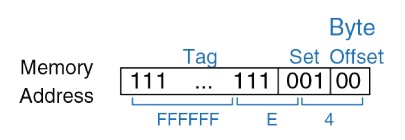
*Рис. 5. Схематичное представление разделения уникального адреса ячейки памяти на составляющие части.*
где
Первые 2 бита (**Byte Offset**) — смещение внутри слова
Следующие три бита (**Set**) указывают, на какой набор претендует ячейка памяти.
Оставшиеся 10 бит представляют собой **Tag**, с помощью которого определяется, находится ли ячейка в кэш-памяти или нет.
**Пример:**
```assembly
addi $t0, $0, 5 # Инициализируем счетчик в регистре $t0 значением 5
loop: beq $t0, $0, done # Загружаем значения из памяти по адресам 0x4, 0xC и 0x8 в регистры $t1, $t2 и $t3 соответственно.
lw $t1, 0x4($0)
lw $t2, 0xC($0)
lw $t3, 0x8($0)
addi $t0, $t0, -1 # Уменьшаем счетчик на 1.
j loop # Повторяем цикл, пока счетчик в регистре $t0 не достигнет нуля.
done:
```
Давайте разберём, как это работает *(рис. 6)*:
У нас есть цикл с 5 итерациями, что означает 15 обращений к памяти. При первом проходе по циклу мы сталкиваемся с промахами и записываем их в ячейки памяти. На последующих итерациях цикла у нас уже будут попадания.
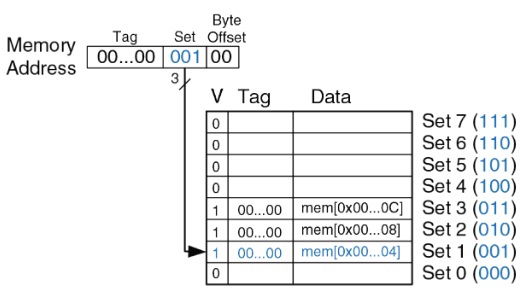
*Рис. 6. Визуализация процесса выполнения ассемблерного кода, представленного выше.*
В итоге из 15 обращений к памяти у нас 3 промаха. Теперь можем рассчитать **MR**:
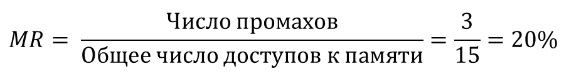
**Пример вытеснения (evict):**
```assembly
addi $t0, $0, 5 # Инициализируем счетчик в регистре $t0 значением 5
loop: beq $t0, $0, done
lw $t1, 0x4($0) # Загружаем значения из памяти по адресу 0x4 в регистр $t1
lw $t2, 0x24($0) # Загружаем значения из памяти по адресу 0x24 в регистр $t2
addi $t0, $t0, -1 # Уменьшаем счетчик на 1.
j loop # Повторяем цикл, пока счетчик в регистре $t0 не достигнет нуля.
done:
```
Загрузка двух ячеек памяти — 4 и 24 — приводит нас к проблеме *(рис. 7)*. Обе эти ячейки ссылаются на один и тот же набор. Из-за этого при каждом обращении к памяти мы будем получать промах.

*Рис. 7. Визуализация процесса выполнения ассемблерного кода, иллюстрирующая проблему вытеснения ячейки памяти с адресами 4 и 24.*
Соответственно, **MR** в данном случае будет 100%:

## Множественно-ассоциативный кэш
Идея множественно-ассоциативного кэша заключается в наличии нескольких строк внутри одного набора. Увеличив ассоциативность, мы теперь имеем двухсекционный кэш (**Way 1** и **Way 0**) *(рис. 8)*. Каждая ячейка памяти может претендовать на любую из этих двух секций, и, в таком случае, вытеснения не произойдет.
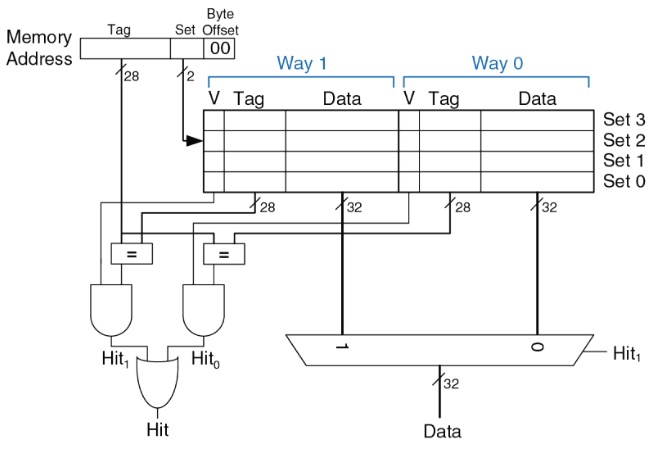
*Рис. 8. Структура множественно-ассоциативного кэша. Отображены две ассоциативные секции — Way 1 и Way 0 — внутри одного набора.*
Но такой кэш *(рис. 9)* сразу будет работать медленнее из-за появившегося мультиплексора на выходе, он более сложен в реализации, кроме того, увеличивается сложность вычислений.
**Тот же пример:**
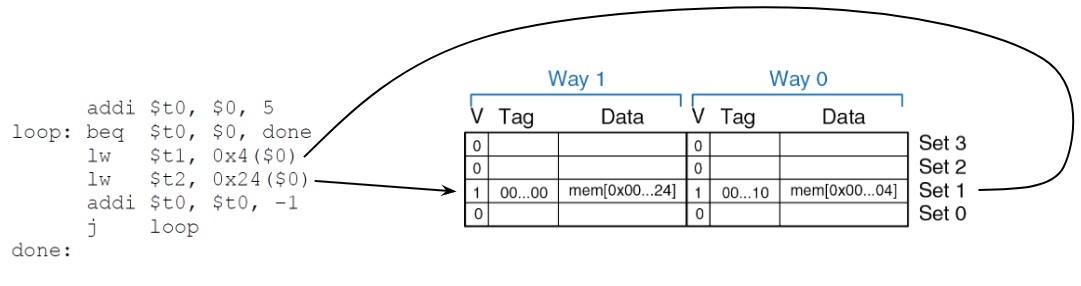
*Рис. 9. При обращении к адресам 0x4 и 0x24 видно, что ячейки памяти могут быть распределены по разным секциям (Way 1 и Way 0), что предотвращает вытеснение.*
Теперь у нас будет два промаха в первом цикле, а уже на следующих мы без проблем сможем обращаться к обеим ячейкам. Таким образом, теперь MR = 20%
## Полностью ассоциативный кэш
В полностью ассоциативном кэше *(рис. 10)* мы оставляем **только один набор**, то есть любая ячейка из памяти может попасть в любую секцию. В таком варианте кэша отлично решается проблема вытеснения, однако реализация становится крайне объемной и медленной, поэтому он находит применение в более специфических местах.

*Рис. 10. Существует только один набор, но с множеством секций, позволяя любой ячейке из памяти быть загруженной в любую доступную секцию кэша.*
### Длина строки (блока)
Если процессор не находит в кэше данные той ячейки памяти, к которой он обращался, он забирает эти данные из основной памяти, одновременно перемещая их в кэш. Как вы знаете, благодаря **пространственной локальности** высока вероятность того, что вскоре процессор обратится и к соседним ячейкам памяти. Поэтому эффективно будет переместить в кэш данные не только этой ячейки памяти, но и данные ячеек памяти, лежащих рядом с ней, образуя **блок данных**. Таким образом, кэш оперирует данными не на уровне ячеек памяти (**слов**), а на уровне блоков ячеек (**строк**). В простейшем случае в одной строке находится одно слово, т.е. кэш загружает только ту ячейку памяти, к которой он обращался.
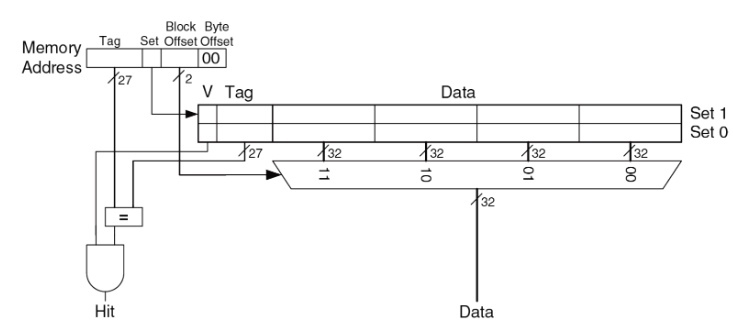
*Рис. 11. Схематическое представление деления адреса в контексте длины строки (или блока) кэша.*
Здесь *(рис. 11)* у нас адрес делится на чуть большее количество секций, байтовое смещение (**Bite Offsets**) для байта внутри одного слова, смещение блока (**Block Offsets**) т.е. смещение внутри строки, бит для выбора набора (**Set**) и 27 бит под **Tag**.
**Плюсы**:
При обращении к одной инструкции из кэша автоматически загружаются и следующие три инструкции, что обеспечивает быстрый доступ к большому объему данных.
**Минусы**:
Пропускная способность канала между процессором и памятью. Промах с длинной строкой будет стоить дороже, чем промах с одним словом.
**Вернемся к первому примеру:**
```assembly
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw $t2, 0x24($0)
addi $t0, $t0, -1
j loop
done:
```
Благодаря размещению всей строки в памяти, у нас будет только один промах, а все последующие обращения приведут к попаданиям.
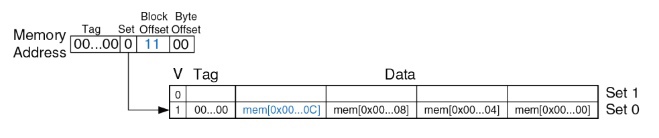
*Рис. 12. Схема демонстрирует эффективность использования строк в кэше, минимизируя количество промахов при последовательных обращениях.*
И теперь мы получим более низкий MR:
## Алгоритмы замещения данных
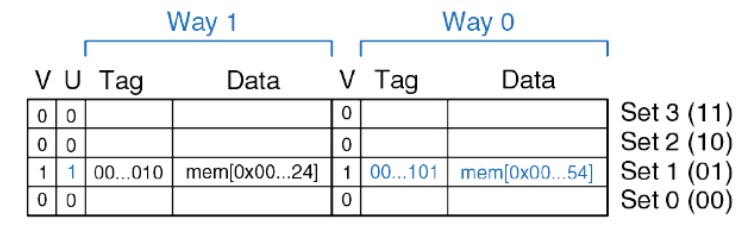
- **LRU** (Least Recently Used) – наиболее давнего использования +
*Рассмотрим на примере двухсекционного кэша *(рис. 13)*, где у нас добавляется дополнительный бит (**U** - used), куда помещается номер секции, которая сейчас не использовалась. Т.е. если сейчас мы записываем в секцию 0, то в этот бит попадает 1, и, если потребуется какую-то из ячеек убрать, устройство управления этим кэшем выберет ту ячейку, которая указана в поле U.*

*Рис. 13. Схема работы алгоритма замещения данных LRU на примере двухсекционного кэша.*
- **PLRU** (Pseudo-Least Recently Used) – псевдо наиболее давнего использования +/–
*Все секции, которые устроены по алгоритму LRU, делятся пополам, а внутри конкретная ячейка выбирается случайным образом.*
- **FIFO** (First In First Out) – замещение в порядке очереди
*Данные выходят в том же порядке, в котором поступали.*
- **LFU** (Least Frequently Used) – наименее частого использования +
*С каждой секцией ассоциирован счетчик, при каждом обращении к секции счетчик у конкретной ячейки увеличивается. Замещается ячейка с наименьшим числом счетчика.*
- **RND** (Random Replacement) – замена случайной строки –
- **CLOCK** – циклический список с указателем +
*Каждой ячейке ассоциирован отдельный бит, устанавливаемый в 1 при обращении к ячейке. В случае необходимости замещения, алгоритм начинает по порядку просматривать данные биты:*
- *в случае, если бит равен 1, то он сбрасывается в 0;*
- *в случае, если бит равен 0, замещается ассоциированная с этим битом ячейка*.
Количество промахов на 1000 обращений к памяти:

*Рис. 14. Табличка сравнения алгоритмов замещения данных в контексте различных размеров кэш-памяти и секций. Как видно из данных, при увеличении объема кэш-памяти разница в количестве промахов между различными алгоритмами уменьшается.*
### Стратегии чтения и записи в кэш
- Стратегии чтения
- Чтение с параллельной выборкой (look-aside)
- Чтение со сквозным просмотром (look-through)
- Стратегии записи
- Сквозная запись (write-through) — пишем сразу и в кэш, и в память
- Сквозная запись с отображением
- Сквозная запись без отображения
- Буферизированная сквозная запись — пишем сразу и в кэш, и в память, но через буфер
- Отложенная запись (write-back) — пишем только при вытеснении из кэша
- В среднем на 10% эффективнее сквозной записи. Чаще используется.
**Многоуровневый кэш.**
Для чего нужны уровни кэша *(рис. 15)*? Давайте проверим, есть ли прирост производительности с помощью AMAT.
*Рис. 15. Пирамида иерархии памяти.*
Допустим:
tL1 = 1
tL2 = 10
tMM = 100
MRL1 = 5%
MRL2 = 20%
*AMAT* = tL1 + MRL1 *(tL2 + MRL2* tMM) = 1 + 0.05 *(10 + 0.2* 100) = 2.5 такта
А теперь уберем кэш второго уровня:
*AMATwithout L2* = 1 + 0.05 * (100) = 6 тактов
Т.е. многоуровневый кэш повышает производительность, но требует больших аппаратных затрат.
Многоуровневый кэш может быть построен по одному из двух принципов:
- Инклюзивный кэш.
*В более низких уровнях памяти содержится копия тех, что выше.*
- Эксклюзивный кэш.
*На более низких уровнях памяти нет копии верхнего уровня.*
## Основные оптимизации кэш-памяти
- Больший размер блока для уменьшения доли промахов.
- Кэши большего объема для уменьшения доли промахов.
- Увеличение ассоциативности для уменьшения доли промахов.
- Многоуровневые кэши для уменьшения потерь на промахах.
- Предоставление приоритета промахам считывания по отношению к записям для уменьшения потерь на промахи.
## Основные материалы лекции
1. [Ссылка](https://youtu.be/1PWTr6RogZQ?list=PL0def37HEo5KHPjwK7A5bd4RJGg4djPVf) на видеозапись лекции
## Дополнительные материалы к лекции для саморазвития